Introduction
This article follows on from my previous post on how serverless can reduce data pipeline costs.
This will give you an overview of how to run Halfpipe in AWS Lambda.
The demo scenario is based around extracting data from SQL Server to S3, but could equally be an Oracle source or Snowflake target etc.
It’s super easy to get going!
How To Run Halfpipe In Lambda
This section is broken into the following headings:
Creating The Lambda
We’ll use the AWS console as a starter.
I’d like to Terraform this to make it easy to repeat elsewhere, but for now I’ve put together a list of steps:
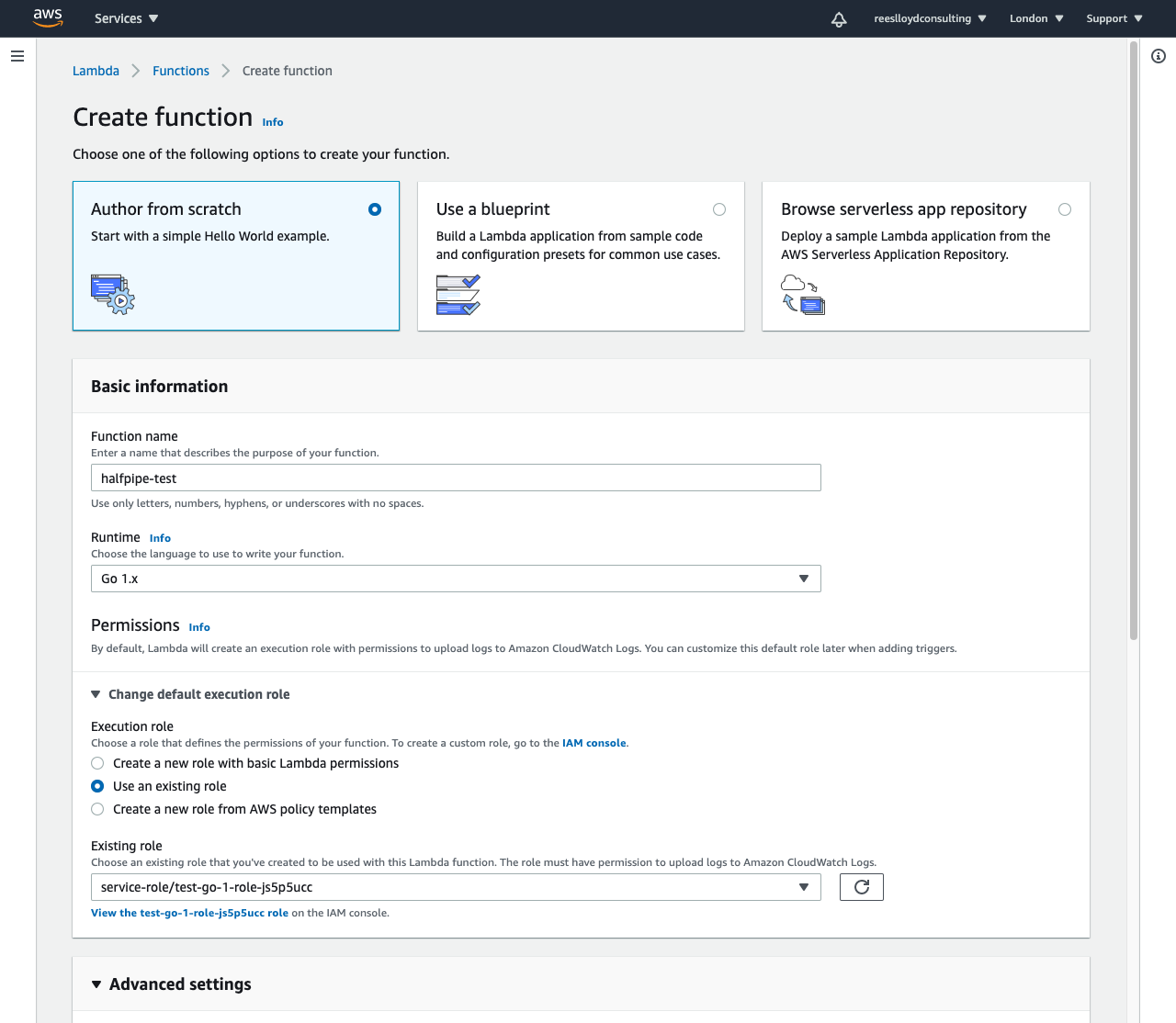
Log into the Console and goto the Lambda service
- Hit “Create function” to get started
- Use the “Author from scratch” option
- Enter a function name
- Choose the Go1.x runtime
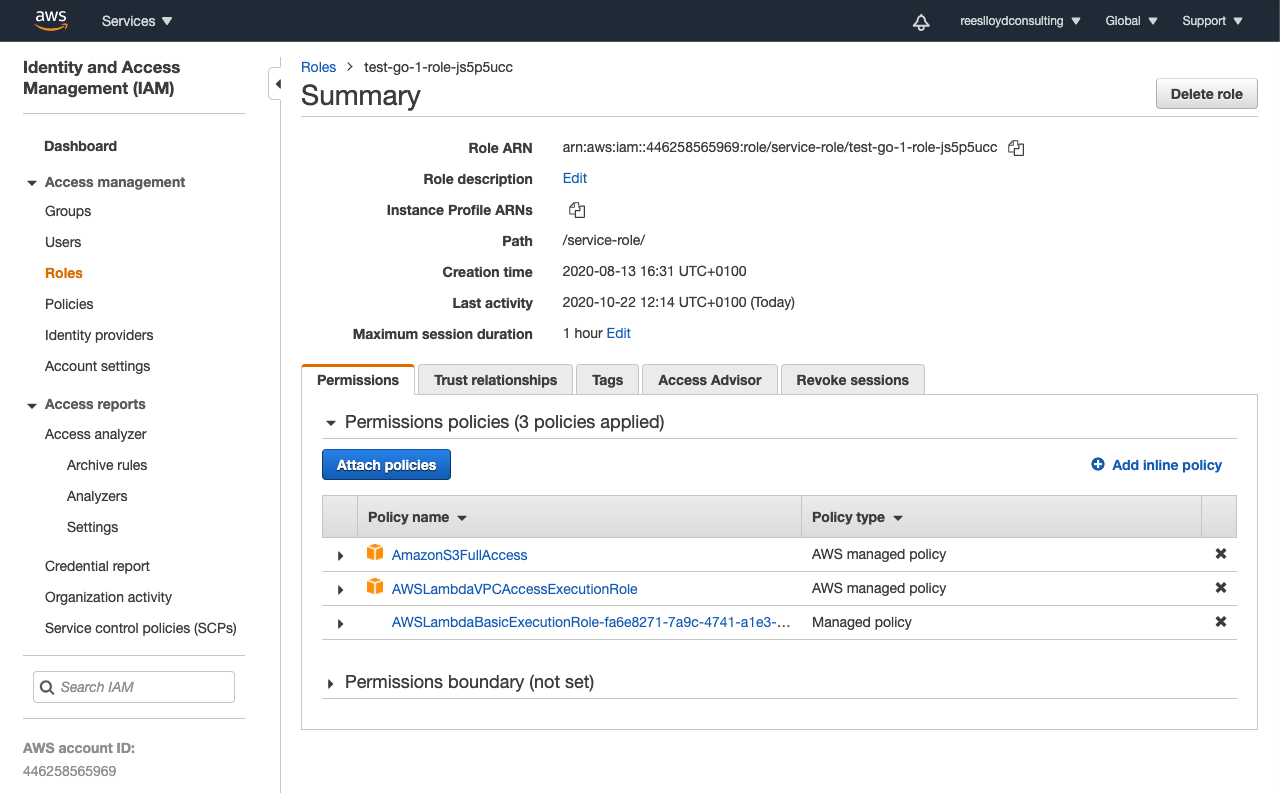
Choose an existing execution role, or create a new one, with the right access levels, to:-
- Your target S3 bucket (CSV files will be written here)
- Your data sources (i.e. the SQL Server instance in this example)
- The Internet (required for Halfpipe to authenticate the HP_AUTH_KEY below)
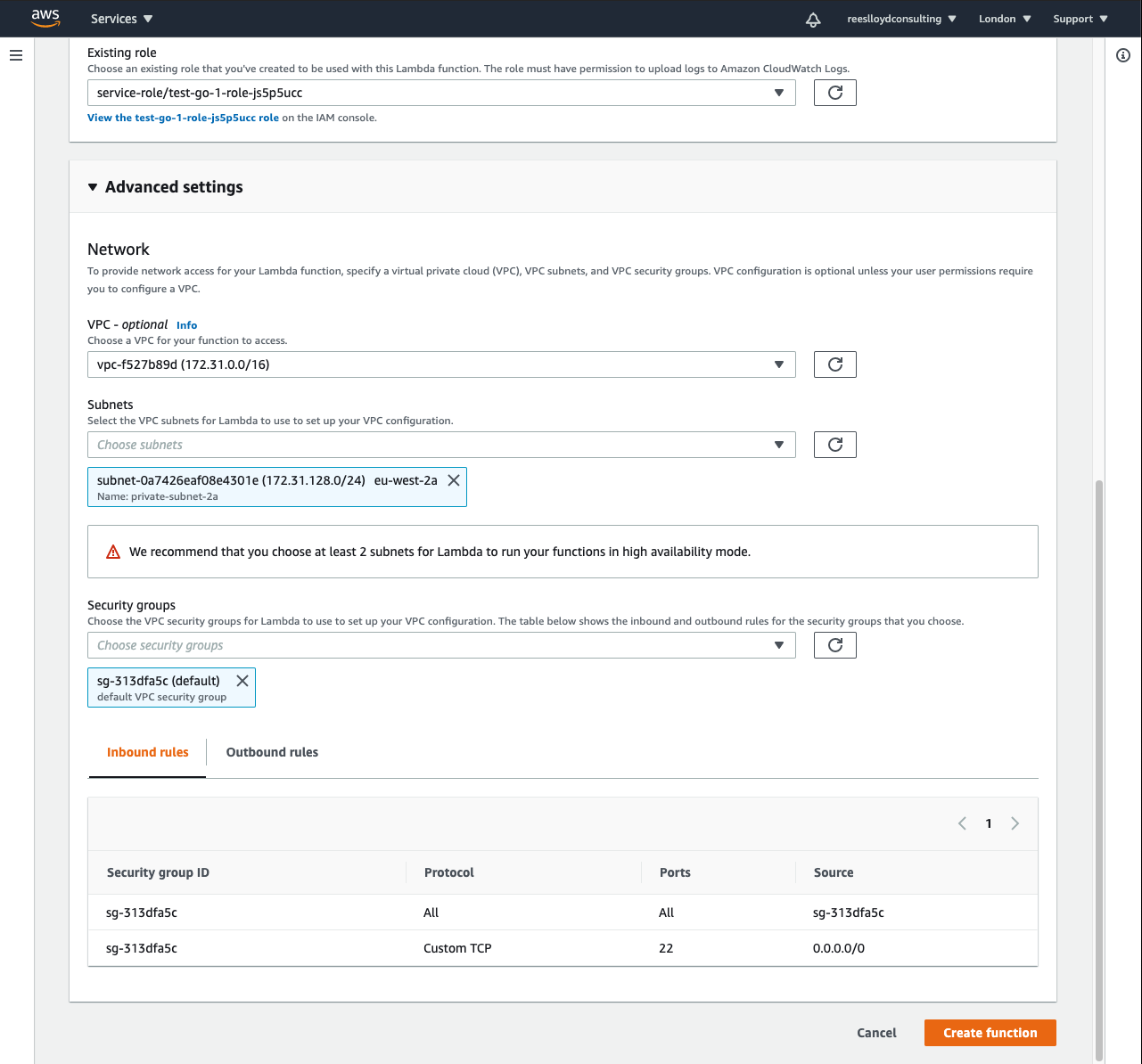
Configure a VPC [optional]
If your source system is running on EC2 like mine then your Lambda will probably need to be in a VPC, else this section is optional:
- Choose a VPC
- Choose your subnets
- Choose a security group
- Ensure you have a NAT gateway for Internet access (required for Halfpipe to authenticate the HP_AUTH_KEY below)
Click “Create function” to continue
Edit the “Function code”
- In this section, select the “Actions” drop-down list and choose “Upload a .zip file”
- Choose to upload the Halfpipe binary zip file:
hp.zip - Hit “Save” to continue
Configure environment variables
- Add an entry for each item in the table below
- This tells Halfpipe how to run without CLI args
- See the screenshots for examples
Edit the “Basic settings”
- Set the Lambda handler to be the name of the unzipped binary:
hp - Choose your RAM size (MB), which determines the CPU resources
- Choose a timeout (max 15 minutes)
- Optionally reconfigure your execution role here (it was set above)
- Click “Save” to continue
- Set the Lambda handler to be the name of the unzipped binary:
Add a Lambda layer [optional]
- This is only required if you want Oracle or ODBC connectivity
- Upload a layer (zip file) using AWS CLI commands below
- Associate the layer with the function using AWS CLI commands below
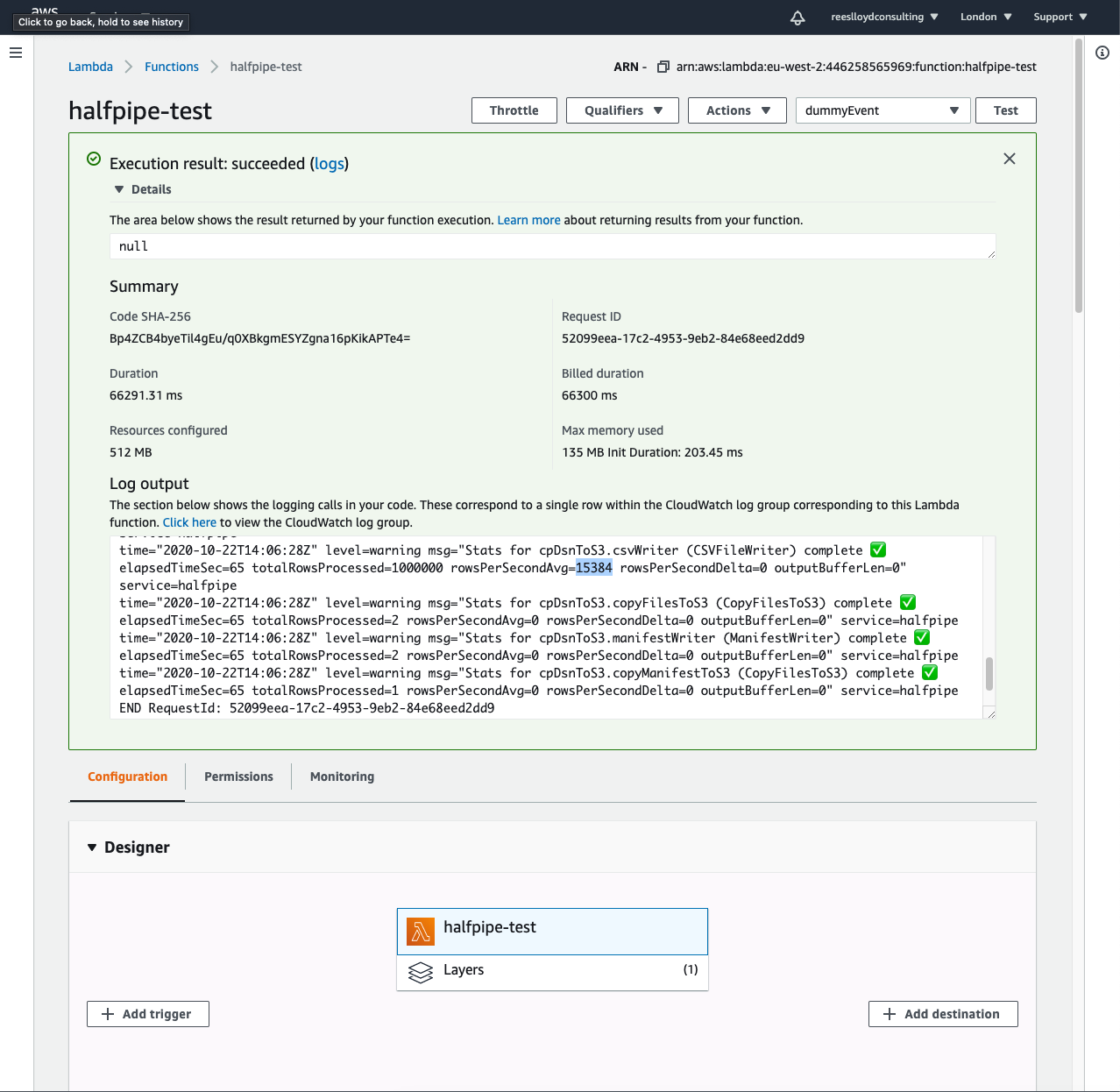
Hit “Test” to extract the source data
- Use the default test event payload provided by the console
- Enter an event name like
dummyEvent - Hit “Create” to return to the main function page
- Hit “Test” to run the extract
- Check the logs to view success/failure
- Check the target S3 bucket for files like those below:
s3://test.halfpipe.sh/halfpipe/sample_data-20201022T140522_000001.csv.gz
s3://test.halfpipe.sh/halfpipe/sample_data-20201022T140522_000002.csv.gz
s3://test.halfpipe.sh/halfpipe/sample_data-20201022T140522_000001.man <<< this manifest contains a list of the above two files to signal a successful extract
Environment Variables
The following environment variables tell Halfpipe how to run without the need for CLI arguments. The aim is for Halfpipe to take a snapshot of source data in SQL Server straight to S3.
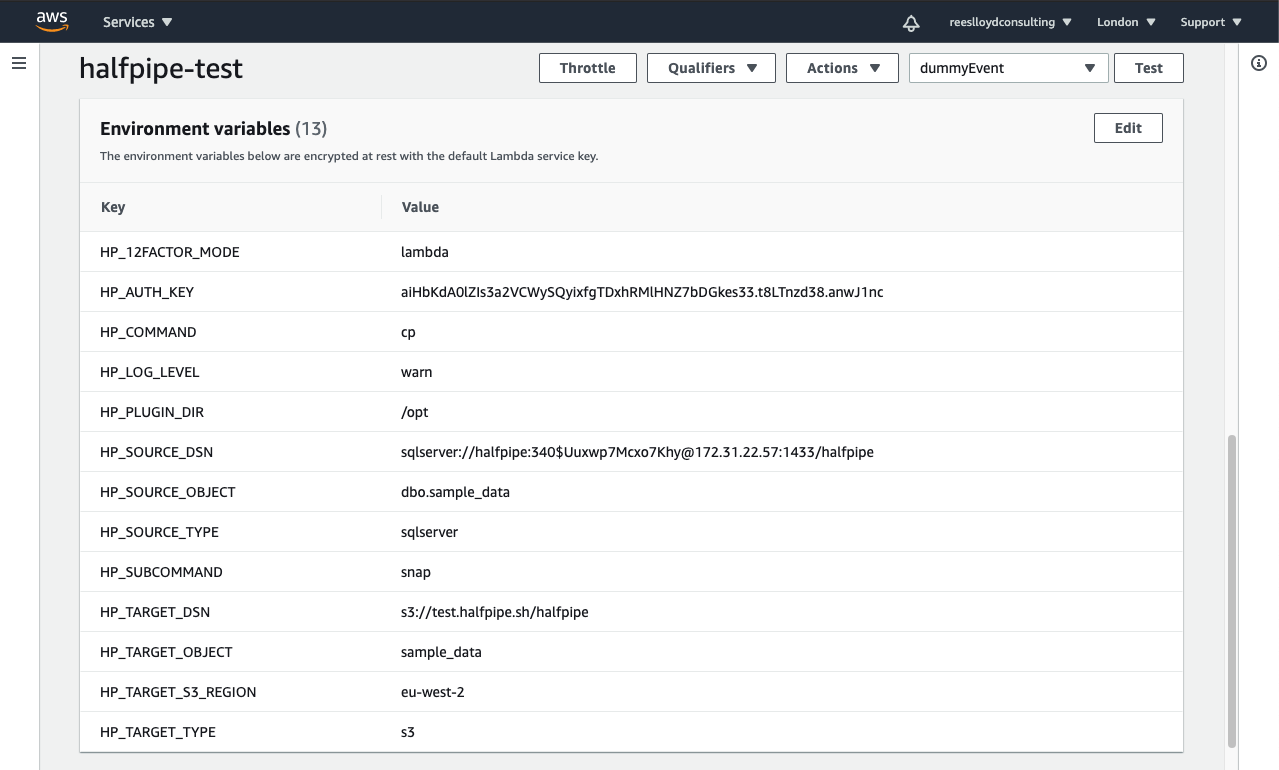
| Variable | Value |
|---|---|
| HP_12FACTOR_MODE | lambda |
| HP_COMMAND | cp |
| HP_SUBCOMMAND | snap |
| HP_SOURCE_DSN | sqlserver://<user>:<password>@<your-host-FQDN>:1433/<your-database> |
| HP_SOURCE_OBJECT | <schema>.<object>table ‘dbo.sample_data’ was used in this example |
| HP_SOURCE_TYPE | `<oracle |
| HP_TARGET_DSN | s3://<bucket>/<prefix>pick your target DSN or bucket |
| HP_TARGET_OBJECT | sample_datause your target S3 object or table name prefix of choice |
| HP_TARGET_S3_REGION | eu-west-2supply your bucket region when the target type is S3 |
| HP_TARGET_TYPE | s3this could be oracle or snowflake |
| HP_AUTH_KEY | aiHbKdA0lZIs3a2VCWySQyixfgTDxhRMlHNZ7bDGkes33.t8LTnzd38.anwJ1ncuse this value for access to snap subcommand for free |
| HP_LOG_LEVEL | warnwarn produces stats only, or use: error, info, debug |
| HP_PLUGIN_DIR | /optsee notes below |
Notes
- The value of HP_COMMAND can be any of the CLI arguments like
cp,sync,pipeetc - The value of HP_SUBCOMMAND can be any of the CLI arguments valid for a given command, like
snap,delta,batch,eventsetc - The source and target DSN can match any of the formats specified in the command usage, see
hp config connections add -h - The
snapsubcommand tells Halfpipe to read all data from the source in the above example - In the screenshot, I’ve just used an IP address when the SQL Server host should really be a DNS entry instead
- The plugin directory path
/opttells Lambda to use contents found at the root of the (optional) Lambda layer (see zip file contents below) - While HP_12FACTOR_MODE is set, for any of the CLI flags mentioned in the
hpcommand usage, it’s possible to specify an equivalent environment variable by using formatHP_<flag-long-name>. Be sure to use upper case and underscores instead of hyphens. - I’d like remove the need to specify HP_SOURCE_TYPE and HP_TARGET_TYPE in future. It’s on the roadmap to simplify things
ToDo
Produce a table of valid source and target types, as well as DSN formats.
How To Extract Deltas Instead
Instead of the snap subcommand, you could use delta to extract records that have changed since the previous execution. This would help reduce the execution time and cost.
You’d need to supply extra variables for the primary key and a delta-driver (date-time or sequence) field as well.
HP_PRIMARY_KEYS=<csv list of key fields>
HP_DELTA_DRIVER=<field name of type date-time or number>
Publishing A Lambda Layer [optional]
This is only required if you want to connect to Oracle databases or use ODBC drivers.
A Lambda layer is really just a zip file stored in a bucket, which will be unpacked and supplied to the Lambda under path /opt when it starts up.
- For Oracle connectivity, the layer needs to contain a Halfpipe plugin
hp-oracle-plugin.soand the OCI libraries - For ODBC connectivity, it needs the ODBC plugin
hp-odbc-plugin.soand unixODBC drivers (not included in the screenshot below)
The following example shows the contents of a layer with the Oracle Basic Light Instant Client unzipped into a working directory structure:
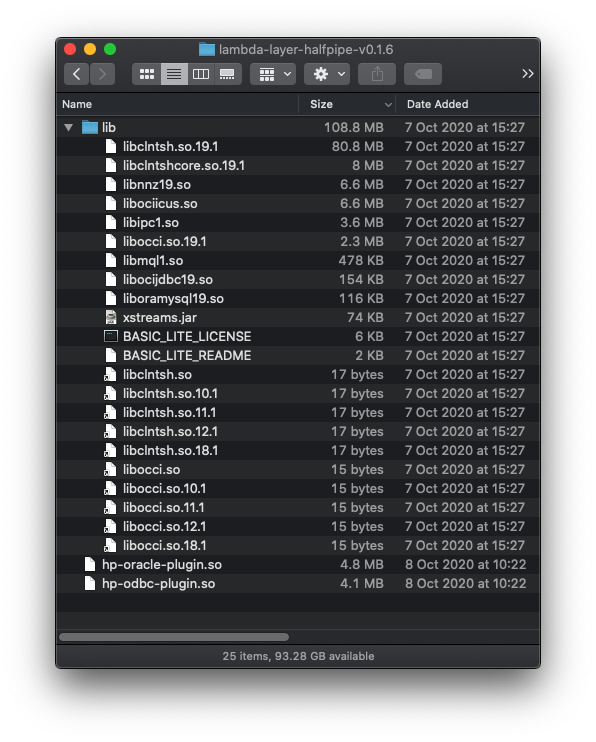
So I created a zip of this directory called lambda-layer-halfpipe-v0.1.6.zip and uploaded it to bucket lambda.halfpipe.sh. Then I published the layer using this AWS CLI command:
aws lambda publish-layer-version \
--layer-name hp-layer \
--description "Halfpipe" \
--content S3Bucket=lambda.halfpipe.sh,S3Key=lambda-layer-halfpipe-v0.1.6.zip \
--compatible-runtimes go1.x
You should get a response that looks something like this. Take a note of the LayerVersionArn for later.
{
"Content": {
"Location": "https://awslambda-eu-west-2-layers.s3.eu-west-2.amazonaws.com/snapshots/446258565969/hp-layer-8dabd3b0-4801-4808-835c-ec408af789ac?versionId=...",
"CodeSha256": "e867X+89ICY6QTrtB1zJGX0TQpj0BDOUovoDpXniXWw=",
"CodeSize": 41949530
},
"LayerArn": "arn:aws:lambda:eu-west-2:446258565969:layer:hp-layer",
"LayerVersionArn": "arn:aws:lambda:eu-west-2:446258565969:layer:hp-layer:1",
"Description": "Halfpipe",
"CreatedDate": "2020-10-22T12:35:21.289+0000",
"Version": 2,
"CompatibleRuntimes": [
"go1.x"
]
}
After publishing the layer, I associated it with the Lambda function by using this CLI command with the LayerVersionArn from above:
aws lambda update-function-configuration \
--function-name halfpipe-test \
--layers arn:aws:lambda:eu-west-2:446258565969:layer:hp-layer:1
You should get a response that looks like this JSON payload, but with values for your environment:
{
"FunctionName": "halfpipe-test",
"FunctionArn": "arn:aws:lambda:eu-west-2:446258565969:function:halfpipe-test",
"Runtime": "go1.x",
...
"Handler": "hp",
...
"Layers": [
{
"Arn": "arn:aws:lambda:eu-west-2:446258565969:layer:hp-layer:1",
"CodeSize": 41949530
}
],
...
"LastUpdateStatus": "Successful"
}
Screenshots Of My Set-Up
Here are some screenshots of my set-up.
It’s worth noting that the IAM role should be configured for least privileges, unlike mine.
Conclusion
In just a few steps, you can create data pipelines in AWS Lambda that continuously migrate data to S3 and cloud warehouses like Snowflake.
When your data volumes are a good fit, Lambda can simplify pipeline infrastructure and reduce platform costs, with high availability out of the box.
To find out more about the logical limits of Lambda and potential cost savings, take a look at my previous blog here.
Best wishes,
– Richard